

|
DL建立者 原创世界 头衔: 记录世界的探险家
|
展开以显示更多内容 |
|||||






 发表于 2021-9-13 17:24
|
发表于 2021-9-13 17:24
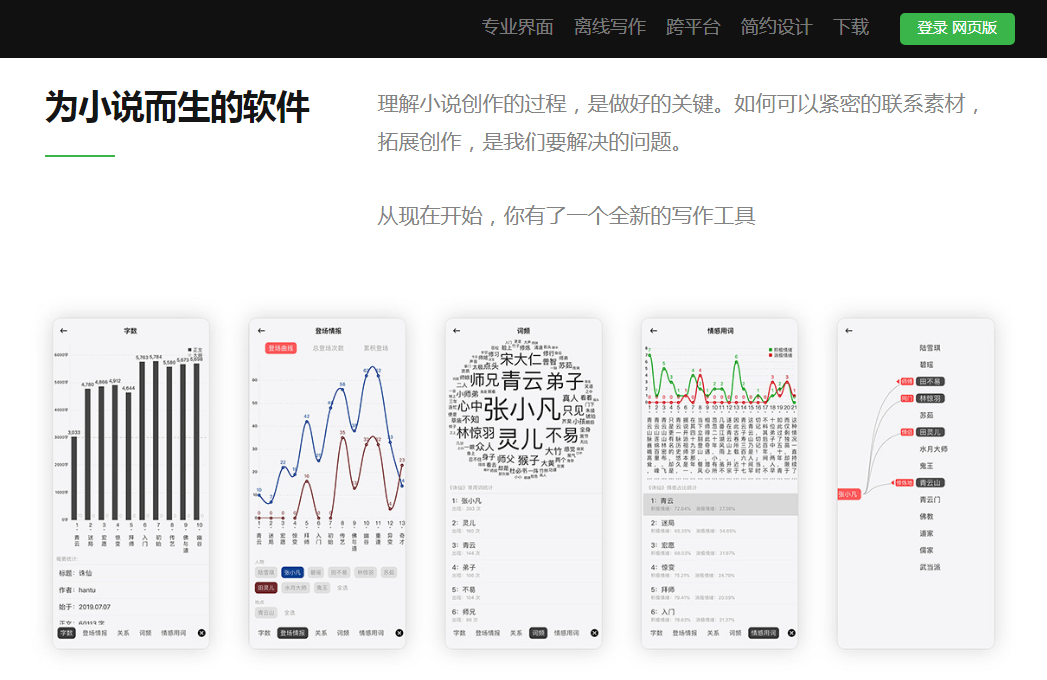
| 

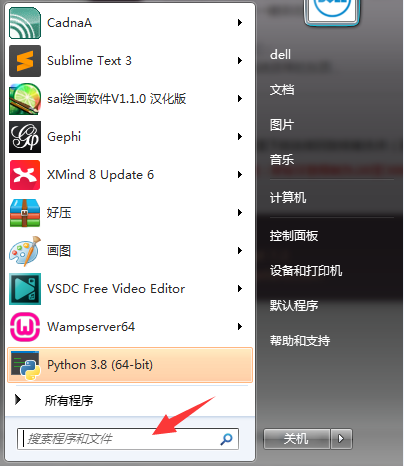
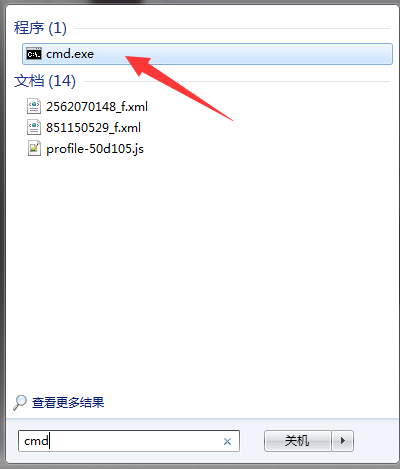
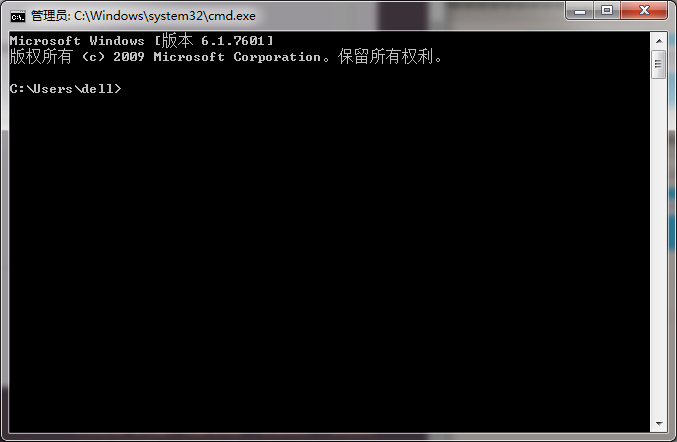



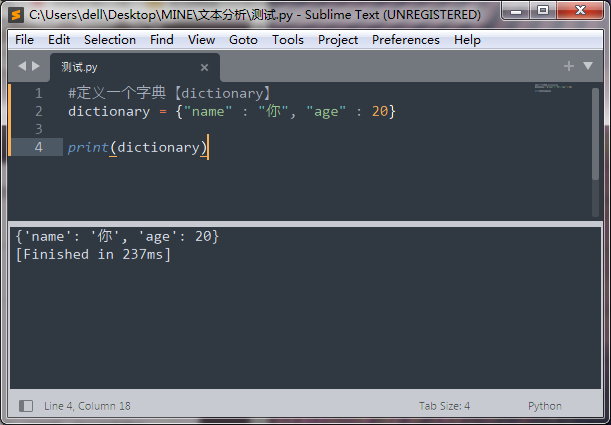
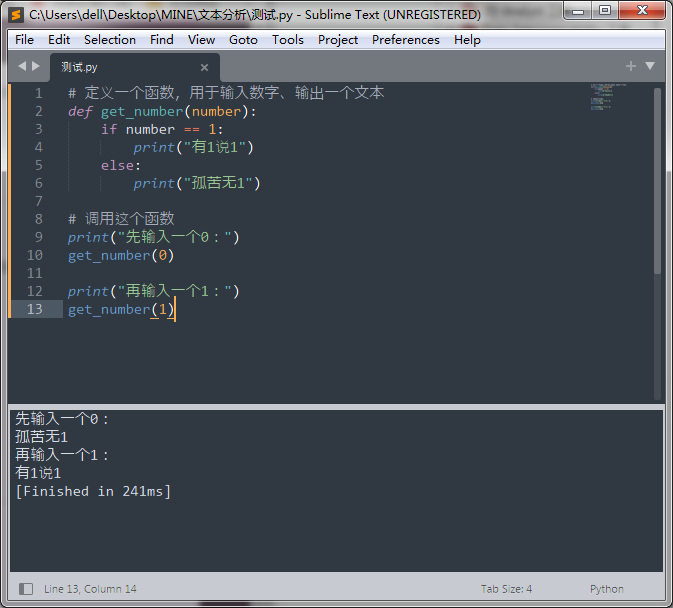
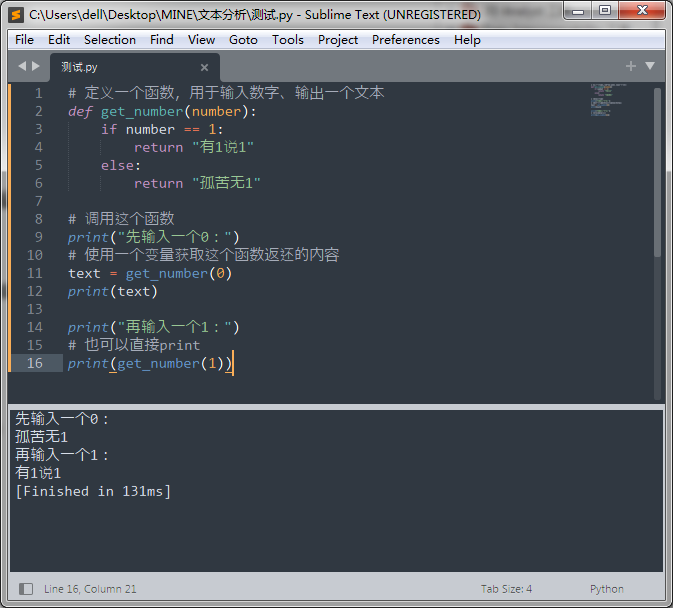
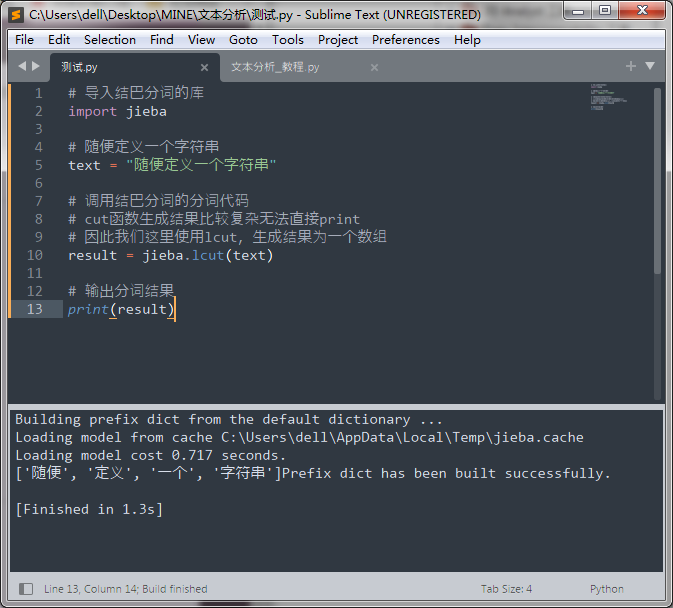

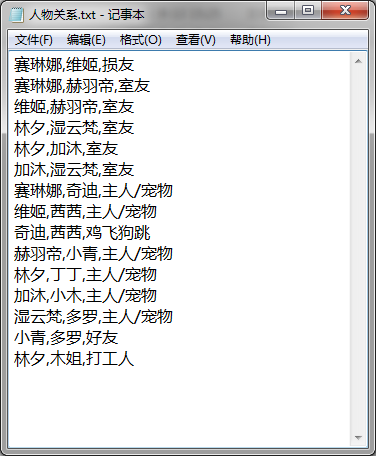

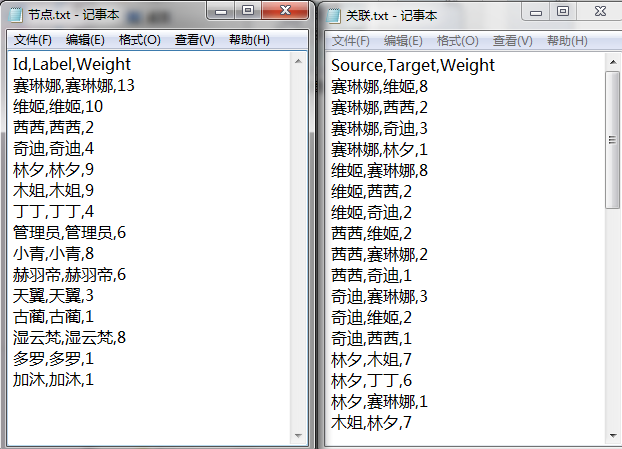
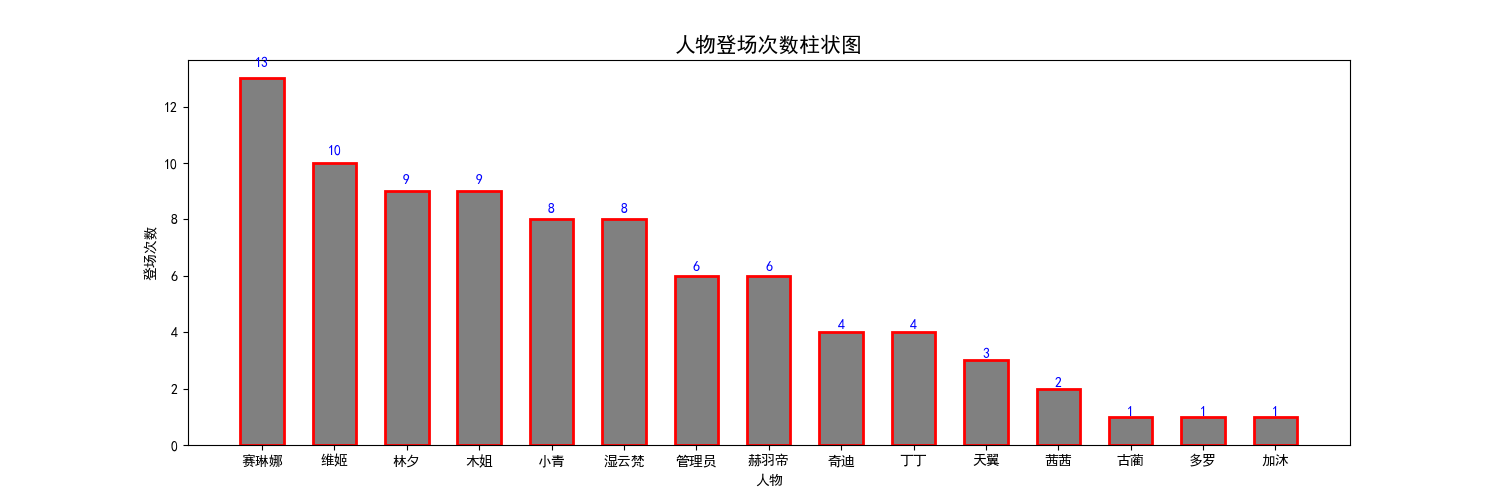


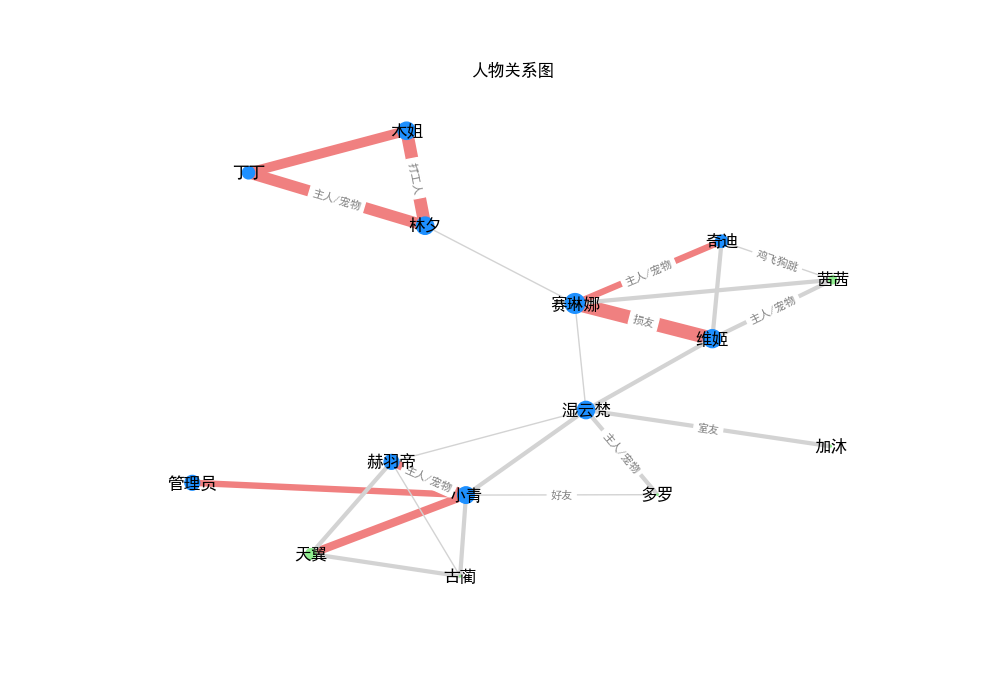


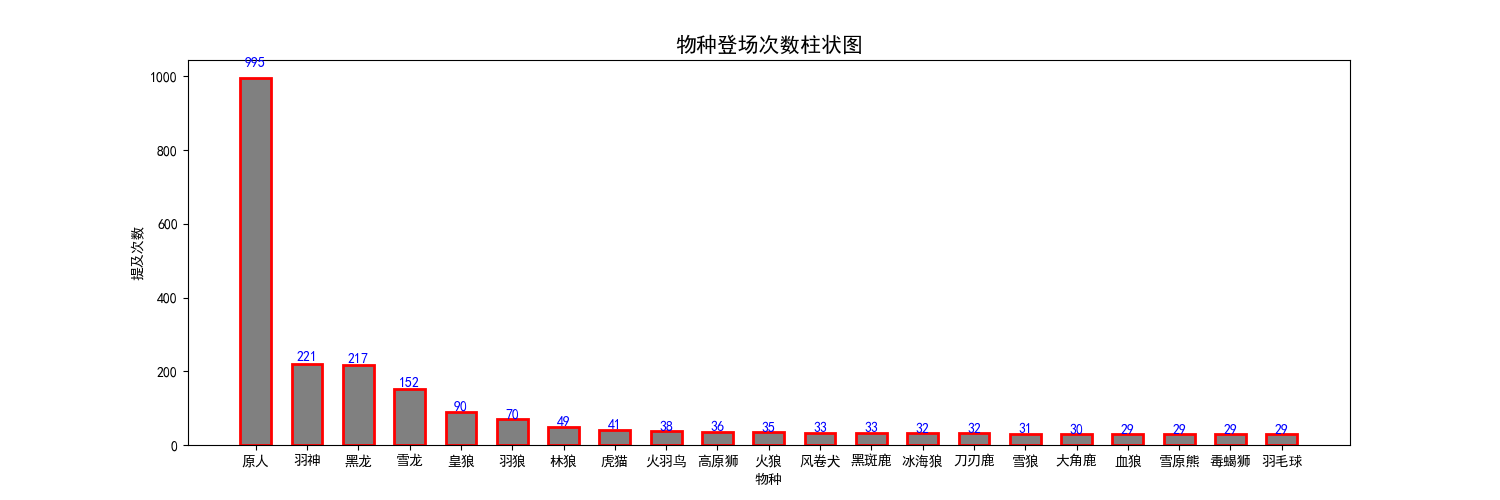

 公版领主
|
展开以显示更多内容 |
|||||
|
愿飞龙常入你的梦乡。
|
||||||
|
|
||||||


 发表于 2021-12-4 11:43
|
发表于 2021-12-4 11:43
|
|
DL建立者 原创世界 头衔: 记录世界的探险家
|
展开以显示更多内容 |
|||||
|
|
||||||

|
公版领主
|
展开以显示更多内容 |
|||||
|
愿飞龙常入你的梦乡。
|
||||||
|
|
||||||
|
DL建立者 原创世界 头衔: 记录世界的探险家
|
展开以显示更多内容 |
|||||
|
|
||||||
